지금은 우리 일상에서 자연스럽게 사용하고 있는 ChatGPT는 사실 처음부터 채팅을 위해서 만들지 않았다는 것을 이 논문을 통해 깨닫게 되었다. 본 논문에서는 총 4가지의 task로 나누어 모델 성능을 평가하였고 각 부분에서 좋은 성능을 보였다. 이 논문을 읽으며 여러 데이터셋을 만날 수 있게 되었는데 관련 데이터 셋에 대한 내용은 노션에 정리해 두었다.
Abstract, Introduction, Related Work section의 중요한 내용을 위주로 Intro에 정리하였다.
Intro
- 대부분의 NLP 처리는(딥러닝) 수동으로 label된 많은 양의 data가 필요
→ labeled data가 없는 부분에서는 적용 가능성(applicability)이 제한됨
- unlabeled data이 label data를 대체해서 얻는 이점
- 시간 소모, 비용 측면에서 대안을 제공
- 모델 성능 대폭 상승
- unlabeled text를 단어 이상으로 활용하는 것에 대한 2가지 문제점
- 어떤 optimization objective가 더 transfer을 text representation에 사용하는 데에 있어 더 효과적인지 unclear
- 학습된 representation을 모델 구조로 보내는 가장 효과적인 방법에 대한 합의(consensus)가 없음
→ semi-supervised learning 접근법을 어렵게 만듦
- GPT-1
- Unsupervised pre-training과 supervised fine-tuning을 결합한 semi-supervise접근을 사용
- Transformer 구조를 사용
- Text의 long-term dependencies에 성능😊
- 구조화된 memory 사용 가능(than RNN)
- 목표 : wide range of tasks에 약간의 조정으로 transfer 할 수 있는 범용 표현을 학습하는 것
- 2단계로 정리
1 ) Unlabeled Data → LM(Language Model) objective 사용
2 ) target task(Supervised objective)에 적용
Framework
Traning 절차는 2개의 단계로 구성 되어 있음.
1. Unsupervised pre-training
2. Supervised fine-tuning
1. Unsupervised pre-training

GPT-1은 Transformer의 decoder의 구조를 가지고 있다. (Encoder: 단어의 vector로 출력/ Decoder: 확률값으로 표현 → 어떤 token이 나와야할지 예측 가능)
하지만 Transformer에서 소개된 decoder 구조와는 달리 (Masked)Multi-head self-attention을 하나만 사용하고 있다는 것을 알 수 있다.
Decoder에서 계산되는 수식은 오른쪽의 구조를 보면 쉽게 이해할 수 있다.


2. Supervised Fine-tuning

⇒ 최종적으로 L1(Unsupervised)과 L2(Supervised)를 이용하 Fine-tuning을 진행
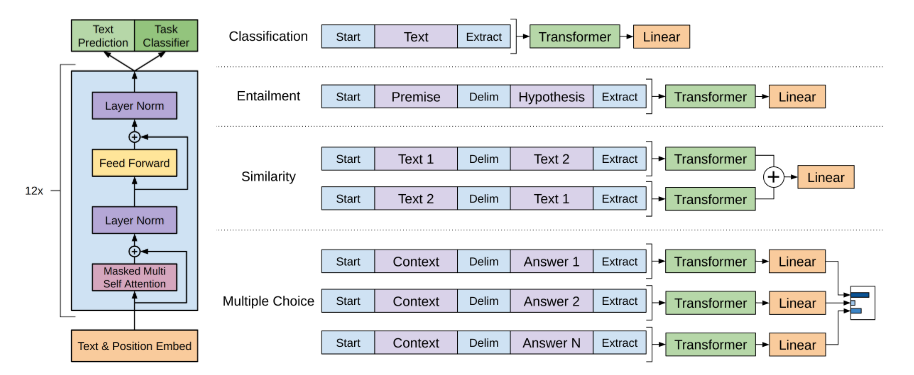
왼쪽 그림에 나온 방식으로 fine-tuning 진행
파란색 부분 : special 토큰들 [Start: BOS 토큰을, Extract: EOS 토큰]
보라색 부분 : 입력 데이터
Transformer : pre-training된 GPT-1 모델
각각 테스크별로 입력을 다르게 만들어서 학습을 진행시키며, pre-training을 진행한 모델을 이용하면, fine-tuning시의 데이터가 적더라도 좋은 성능을 보여주었음.
이때 논문에서 데이터 셋을 분류하여 실험한 테스크는 아래와 같다.

모델을 만들게 된 배경과 어떤 Framework를 가지고 작동을 하였는지에 대해서만 간단하게 정리해 보았다. 이후에 나온 Analysis, Conclusion은 Notion을 통해 확인 가능하다.
'MAD Learning > NLP' 카테고리의 다른 글
| [논문 리뷰] ELMo : Deep contextualized word representations (0) | 2024.02.24 |
|---|---|
| [ 논문 리뷰 ] BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2024.02.18 |
| [논문 리뷰] Transformer : Attention Is All You Need (0) | 2024.02.03 |
| Encoding VS Embedding (0) | 2024.01.31 |
| Subword Segmetation Algorithm(BPE, Wordpiece, Unigram) (0) | 2024.01.27 |



